
The forward pass of Neural Networks itself is already looks very daunting, but in order for us to understand Neural Networks well this post would be a guideline.
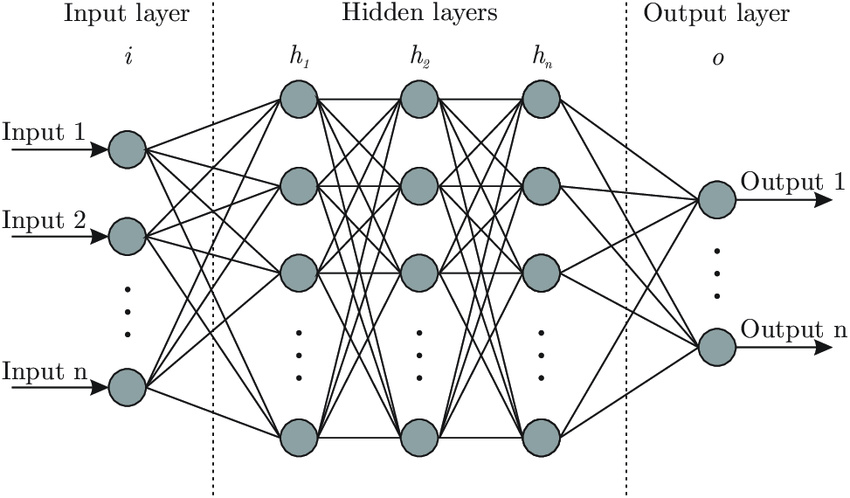
This diagram illustrates the structure of a neural network. The circles represent the neurons, and the connecting lines symbolize the connections between them. In this network, there are several layers: the input layer, three hidden layers, each comprising four neurons, and the output layer. The process begins with the input layer, where, for example, distinct data points are introduced. These inputs are then propagated forward to the first hidden layer, which processes the information and sends it to the second hidden layer. After further processing, the data reaches the output layer. The aim is for the network to process the inputs through these layers and connections to yield the desired output.
Neural networks strive to map input to the desired output, crucially hinging on the fine-tuning of weights and biases. In essence, by meticulously calibrating these parameters during the training process, the network learns to discern and predict new examples, like differentiating between unseen images of cats and dogs. The crux of a neural network’s success lies in this precise tuning of weights and biases, which dictates its ability to generalize from training data to real-world applications.
Enough talking lets dive in. So, let’s say there are 3 neurons that are feeding into this neuron that we are going to build.
inputs = [1.5, 2.4, 17.2]
Those are the unique inputs So these are outputs from the three neurons in the previous layer Every unique input is also going to have a unique weight associated with it.
weights = [3.2, 1.3, 1.4]
Every unique neurons have bias. As for now we will just set the bias to 4.
bias = 4
The initial step for a neuron involves computing the sum of all input values multiplied by their respective weights and then adding the bias. This calculation is quite straightforward and can be performed in plain Python without the need for loops at this point.
output = inputs[0] * weights[0] + inputs[1] * weights[1] + inputs[2] * weights[2] + bias

we’ll continue steadily progressing through ‘Neural Networks with Numpy.’ As demonstrated, the concepts are quite straightforward at this stage, and they’re essentially about adding more elements to what we’ve already dissected. We aim to simplify each subsequent part to the extent that it appears remarkably similar to what’s been covered. While there may be a few more complex topics ahead, the objective remains to make it extremely easy to grasp.